This course is an introduction into formal concept analysis (FCA), a mathematical theory oriented at applications in knowledge representation, knowledge acquisition, data analysis and visualization. It provides tools for understanding the data by representing it as a hierarchy of concepts or, more exactly, a concept lattice. FCA can help in processing a wide class of data types providing a framework in which various data analysis and knowledge acquisition techniques can be formulated. In this course, we focus on some of these techniques, as well as cover the theoretical foundations and algorithmic issues of FCA.
Class Deals by MOOC List - Click here and see Coursera's Active Discounts, Deals, and Promo Codes.
Upon completion of the course, the students will be able to use the mathematical techniques and computational tools of formal concept analysis in their own research projects involving data processing. Among other things, the students will learn about FCA-based approaches to clustering and dependency mining.
The course is self-contained, although basic knowledge of elementary set theory, propositional logic, and probability theory would help.
End-of-the-week quizzes include easy questions aimed at checking basic understanding of the topic, as well as more advanced problems that may require some effort to be solved.
Syllabus
WEEK 1
Formal concept analysis in a nutshell
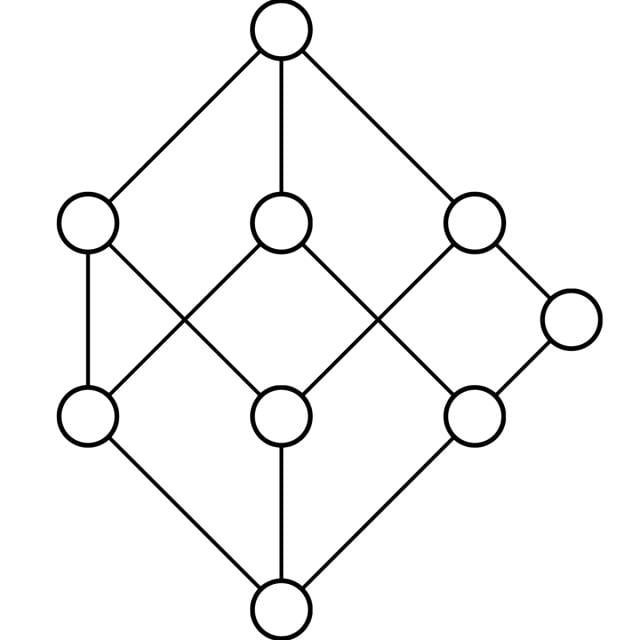
This week we will learn the basic notions of formal concept analysis (FCA). We'll talk about some of its typical applications, such as conceptual clustering and search for implicational dependencies in data. We'll see a few examples of concept lattices and learn how to interpret them. The simplest data structure in formal concept analysis is the formal context. It is used to describe objects in terms of attributes they have. Derivation operators in a formal context link together object and attribute subsets; they are used to define formal concepts. They also give rise to closure operators, and we'll talk about what these are, too. We'll have a look at software called Concept Explorer, which is good for basic processing of formal contexts. We'll also talk a little bit about many-valued contexts, where attributes may have many values. Conceptual scaling is used to transform many-valued contexts into "standard", one-valued, formal contexts.
WEEK 2
Concept lattices and their line diagrams
This week we'll talk about some mathematical properties of concepts. We'll define a partial order on formal concepts, that of "being less general". Ordered in this way, the concepts of a formal concept constitute a special mathematical structure, a complete lattice. We'll learn what these are, and we'll see, through the basic theorem on concept lattices, that any complete lattice can, in a certain sense, be modelled by a formal context. We'll also discuss how a formal context can be simplified without loosing the structure of its concept lattice.
WEEK 3
Constructing concept lattices
We will consider a few algorithms that build the concept lattice of a formal context: a couple of naive approaches, which are easy to use if one wants to build the concept lattice of a small context; a more sophisticated approach, which enumerates concepts in a specific order; and an incremental strategy, which can be used to update the concept lattice when a new object is added to the context. We will also give a formal definition of implications, and we'll see how an implication can logically follow from a set of other implications.
WEEK 4
Implications
This week we'll continue talking about implications. We'll see that implication sets can be redundant, and we'll learn to summarise all valid implications of a formal context by its canonical (Duquenne–Guigues) basis. We'll study one concrete algorithm that computes the canonical basis, which turns out to be a modification of the Next Closure algorithm from the previous week. We'll also talk about what is known in database theory as functional dependencies, and we'll show how they are related to implications.
WEEK 5
Interactive algorithms for learning implications
What if we don't have a direct access to a formal context, but still want to compute its concept lattice and its implicational theory? This can be done if there is a domain expert (or an oracle) willing to answer our queries about the domain. We'll study an approach known as learning with queries that addresses this setting. We'll get to know a few standard types of queries, and we'll see how an implication set can be learnt in time polynomial of its size with so called membership and equivalence queries. We'll then introduce attribute exploration, a method from formal concept analysis, which may require exponential time, but which uses different queries, more suitable for building implicational theories and representative samples of subject domains.
WEEK 6
Working with real data
A concept lattice can be exponentially large in the size of its formal context. Sometimes this can be due to noise in data. We'll study a few heuristics to filter out noisy concepts or select the most interesting concepts in a large lattice built from real data: stability and separation indices, concept probability, iceberg lattices. We will also talk about association rules, which is a name for implications that are supported by strong evidence, but may still have counterexamples in data.