When we use programming for problem-solving purposes, data must be stored in certain forms, or Data Structures, so that operations on that data will yield a specific type of output.
When we use programming for problem-solving purposes, data must be stored in certain forms, or Data Structures, so that operations on that data will yield a specific type of output. Imagine, for example, that a non-profit is having trouble staying afloat and needs an increase in donation. It decides it wants to keep track of its donors in a program in order to figure out who is contributing and why. You would first need to define the properties that would define those donors: name, address, amount donated, date of donation, and so on. Then, when the non-profit wants to determine how to best reach out to their donors, it can create a model of the average donor that contributes to the non-profit—say, for example, based on size of gift and location—so that it can better determine who is most receptive to its mission. In this case, size of gift and location are the “data” of the donor model. If the non-profit were to use this model, it would be identifying real donors by first generating an abstract donor. This is an example of using Abstract Data Types.
Upon successful completion of this course, the student will be able to:
Identify elementary Data Structures using C/C++ programming languages.
Analyze the importance and use of Abstract Data Types (ADTs).
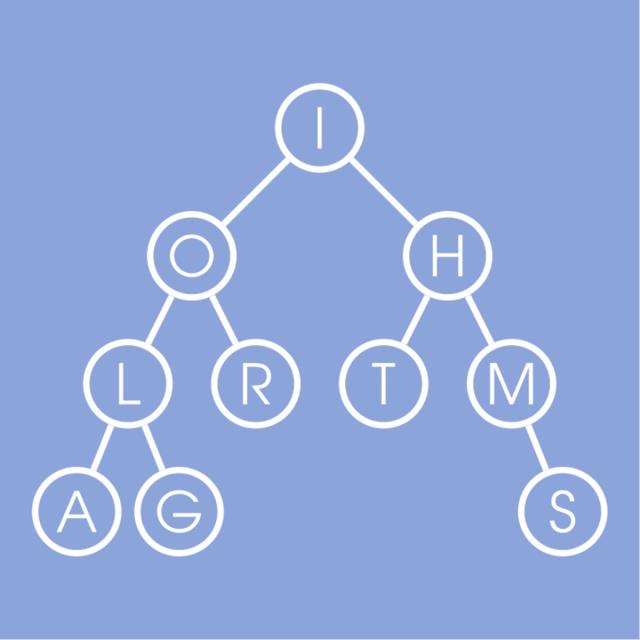
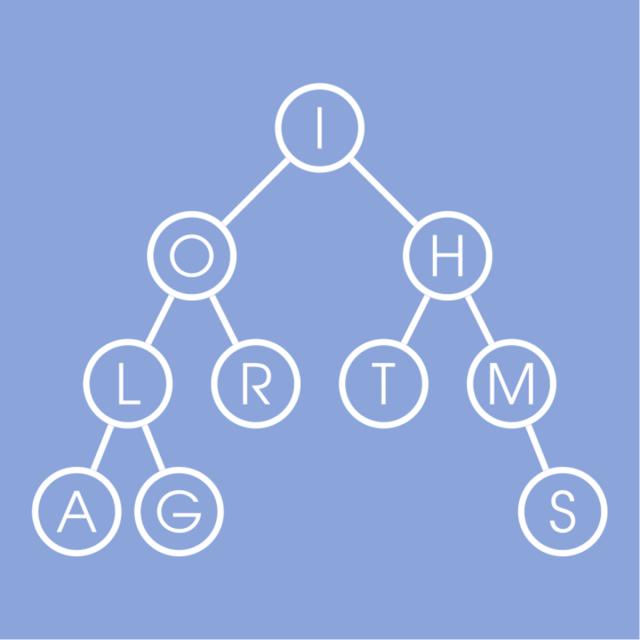
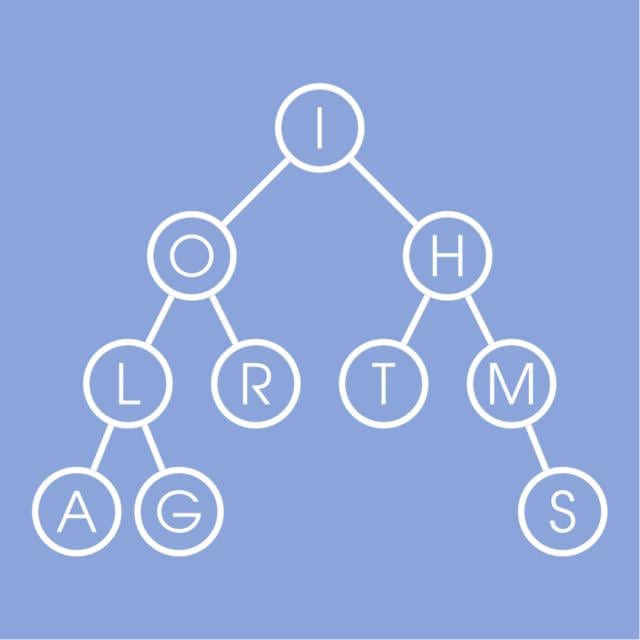
Design and implement elementary Data Structures such as arrays, trees, Stacks, Queues, and Hash Tables.
Explain best, average, and worst-cases of an algorithm using Big-O notation.
Describe the differences between the use of sequential and binary search algorithms.